Questões de Concurso
Foram encontradas 901 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Q1892804
Programação
Natasha, uma cientista de dados, está trabalhando com um
conjunto de dados sobre carros para fazer um modelo preditivo
para uma companhia de seguros. A primeira versão do modelo
utiliza apenas informações básicas sobre os carros: a marca e a
cor.
Como esses dados são categóricos, Natasha faz um pré-processamento usando a biblioteca scikit-learn. Em um ambiente interativo, ela executa os comandos a seguir.
>>> from sklearn.preprocessing import OneHotEncoder >>> enc = OneHotEncoder() >>> X = [['Toyota', 'vermelho'], ['Toyota', 'verde'], ['BMW', 'vermelho']]
>>> enc.fit(X) >>> enc.get_feature_names() array(['x0_BMW', 'x0_Toyota', 'x1_verde', 'x1_vermelho'], dtype=object)
>>> X_prime = enc.transform(X).toarray() >>> X_prime array([[0., 1., 0., 1.], [0., 1., 1., 0.], [1., 0., 0., 1.]])
Para contar o número de carros da marca Toyota no conjunto de dados, obtendo corretamente o resultado 2, Natasha pode usar a seguinte linha de código:
Como esses dados são categóricos, Natasha faz um pré-processamento usando a biblioteca scikit-learn. Em um ambiente interativo, ela executa os comandos a seguir.
>>> from sklearn.preprocessing import OneHotEncoder >>> enc = OneHotEncoder() >>> X = [['Toyota', 'vermelho'], ['Toyota', 'verde'], ['BMW', 'vermelho']]
>>> enc.fit(X) >>> enc.get_feature_names() array(['x0_BMW', 'x0_Toyota', 'x1_verde', 'x1_vermelho'], dtype=object)
>>> X_prime = enc.transform(X).toarray() >>> X_prime array([[0., 1., 0., 1.], [0., 1., 1., 0.], [1., 0., 0., 1.]])
Para contar o número de carros da marca Toyota no conjunto de dados, obtendo corretamente o resultado 2, Natasha pode usar a seguinte linha de código:
Q1892799
Estatística
A demanda de um certo serviço público no mês t é modeladapela equação 20 + 3t + 2D(t) + εt, onde D(t) = 1, se t = 6, e 0, casocontrário, e ε é um ruído com média zero e variância 4.
As previsões de demanda nos meses 6 e 12 são, respectivamente:
As previsões de demanda nos meses 6 e 12 são, respectivamente:
Q1892798
Estatística
Numa empresa com 100 funcionários, todos foram perguntados a
respeito de suas preferências sobre trabalho remoto ou
presencial. Dos funcionários de 18 a 39 anos, 40% preferem
trabalho presencial. Dos funcionários acima de 40 anos, 40%
mostraram preferência pelo remoto. Dos 100 funcionários, 50
têm mais de 40 anos. O presidente da empresa está interessado
em saber se a preferência por trabalho remoto é independente
da categoria de idade (18 a 39 e acima de 40 anos).
O teste a ser usado pelo presidente e o valor da estatística de teste são, respectivamente:
O teste a ser usado pelo presidente e o valor da estatística de teste são, respectivamente:
Q1892797
Estatística
A média e a variância de uma distribuição binomial são,
respectivamente, 20 e 4.
O número de ensaios (n) dessa distribuição é:
Q1892796
Estatística
O histograma a seguir mostra a quantidade de refeições para
cada faixa de preço, em uma determinada área do Rio de Janeiro.
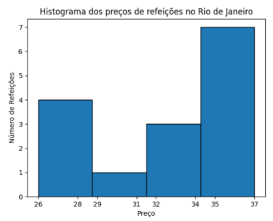
O conjunto de dados consistente com o histograma é: